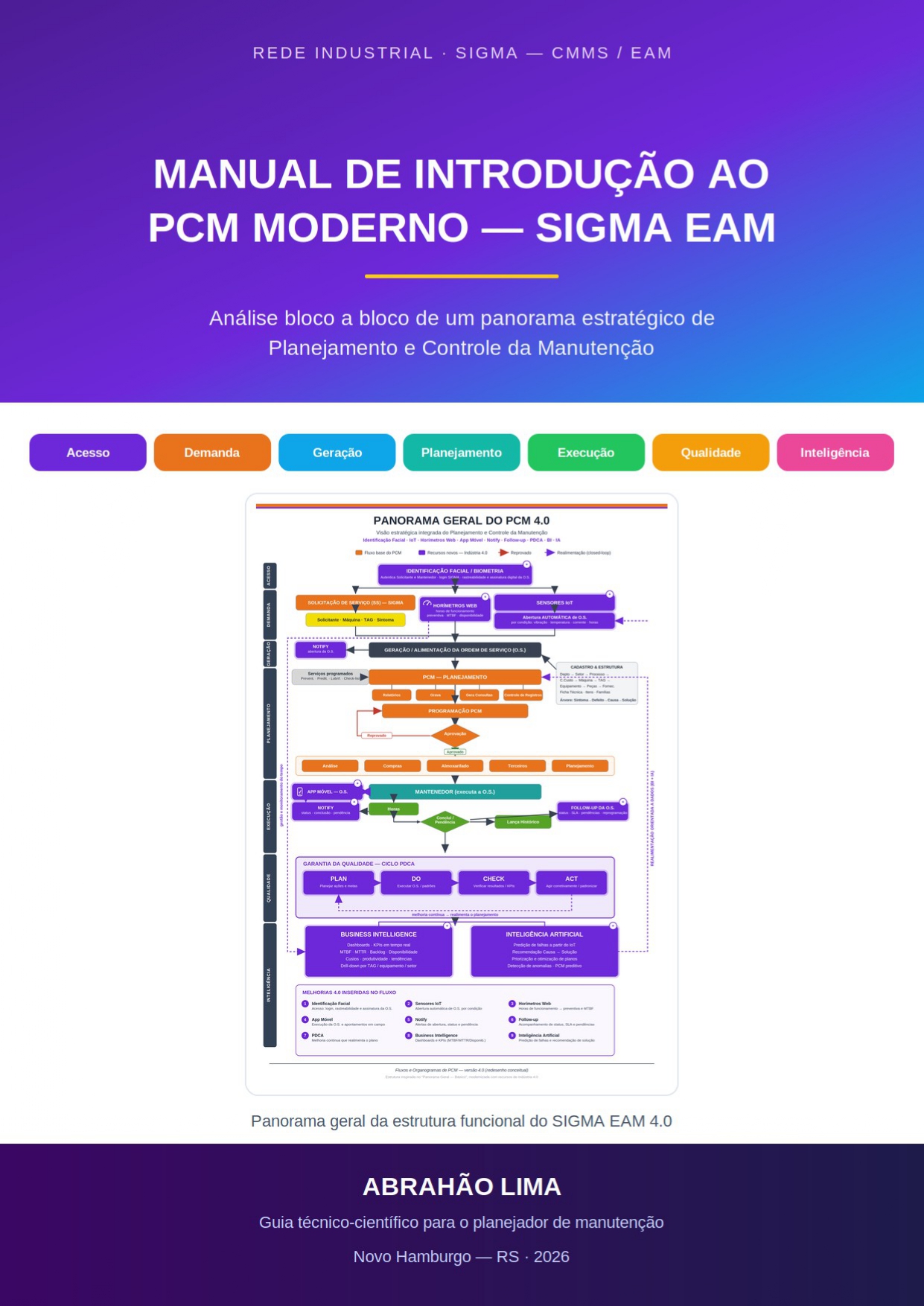
GESTÃO MODERNA DA MANUTENÇÃO UTILIZANDO SIGMA CMMS
Inteligência Artificial integrada ao fluxo de operações
O que é e principais características
Case de uso (exemplo): priorização assistida e redução de reincidência
Em um cenário com grande volume de solicitações, o PCM perde tempo classificando criticidade e buscando histórico para priorizar. Com a IA integrada ao SIGMA CMMS, utiliza-se o histórico de falhas, tempos e custos para sugerir fila de atendimento e ações prováveis, destacando ocorrências recorrentes por ativo e modos de falha. Na prática, solicitações com padrão de reincidência são sinalizadas e encaminhadas para análise mais profunda, enquanto demandas rotineiras seguem fluxo padrão. O efeito esperado é reduzir triagem manual e aumentar a qualidade do diagnóstico, encurtando o ciclo de atendimento e diminuindo repetição de defeitos.
- • KPIs: tempo de triagem do PCM, reincidência (30/60/90 dias), MTTR e % OS com códigos de falha/causa/ação preenchidos corretamente.
- • Boa prática: iniciar com um piloto em 10–30 ativos críticos e ajustar regras de aprovação humana para eventos de alto risco/custo.
- ● Análise automática de dados operacionais: usa históricos de falhas, ordens de serviço, tempos (MTTR/MTBF), custos e eventos para encontrar padrões e desvios.
- ● Sugestão de ações de manutenção: recomenda intervenções preventivas/corretivas e priorização de O.S. com base em criticidade e comportamento do ativo.
- ● Apoio à análise de falhas e causa raiz: correlaciona sintomas, intervenções anteriores e registros técnicos para acelerar diagnóstico e reduzir reincidência.
- ● Apoio à decisão operacional: auxilia no planejamento (PCM), na fila de prioridades e na distribuição de recursos (mão de obra/terceiros/peças) para reduzir atrasos.
- ● Aprendizado contínuo: quanto maior a disciplina de registro (códigos de falha, tempos, materiais, evidências), mais consistentes tendem a ser as recomendações.
Aplicações práticas na gestão da manutenção de ativos
- • Triagem e priorização de solicitações e O.S.: usar a IA para classificar criticidade (segurança, produção, qualidade) e sugerir a melhor fila de atendimento.
- • Recomendação de ações e planos: a partir do histórico do ativo, sugerir ajustes em planos preventivos (periodicidade, checklists, itens) e gatilhos para inspeções/preditivas.
- • Melhoria de qualidade cadastral: identificar inconsistências (cadastros incompletos, códigos de falha divergentes, centros de custo errados) e orientar correções para melhorar relatórios e BI.
- • Suporte ao técnico em campo: sugerir hipóteses de causa e passos de diagnóstico com base em intervenções semelhantes (reduzindo tentativas e erro).
Como reduz custos
Os principais vetores de economia vêm da redução de corretivas emergenciais (que costumam ter maior custo total), da diminuição de retrabalho por diagnóstico mais rápido e da melhoria do planejamento. Na prática, isso tende a reduzir: horas extras, compras urgentes, deslocamentos improdutivos, tempo de parada e consumo de sobressalentes por substituição desnecessária.
Como aumenta produtividade
- • Menos tempo de triagem: classificação assistida reduz o tempo do PCM para entender demanda e montar a programação.
- • Menos tentativa e erro: recomendações baseadas em histórico encurtam o ciclo “diagnosticar → executar → testar”.
- • Padronização: orientações automáticas reduzem variações na forma de registrar e executar, elevando consistência.
KPIs recomendados
- • MTTR (por família de ativo) e suas parcelas: espera por peça, espera por liberação, execução
- • Reincidência de falhas: mesmo modo de falha em 30/60/90 dias
- • % O.S. com causa/código de falha preenchido corretamente
- • Horas extras e compras emergenciais
Roteiro de implantação (boas práticas)
- Qualidade do dado primeiro: padronizar classes de ativos, centros de custo, códigos de falha/causa/ação e procedimentos.
- Piloto controlado: escolher 10–30 ativos críticos e rodar 4–8 semanas com disciplina de apontamentos e evidências.
- Regras de uso: definir quando a IA sugere e quando exige aprovação humana (segurança, parada total, alto custo).
- Ritual de gestão: reuniões semanais de PCM/confiabilidade para revisar recomendações e transformar em ações (planos, sobressalentes, melhorias).
Follow-up automático e disciplina de execução
O que é e principais características
O Follow-up é um conjunto de automações do SIGMA CMMS voltado para garantir acompanhamento contínuo de cada etapa da vida de uma solicitação e de uma ordem de serviço (O.S.). Na prática, ele reduz “zonas cinzentas” típicas do PCM (tarefas esquecidas, OS paradas sem dono, atrasos sem aviso, dependências não mapeadas e falta de retorno para operação), criando rastreabilidade e disciplina de execução.
Case de uso (exemplo): OS parada por material com escalonamento e SLA
Uma OS crítica é planejada, mas entra em status “aguardando peça”. Sem disciplina, ela tende a ficar esquecida até virar emergência. Com o Follow-up do SIGMA CMMS, a pendência fica explícita, com responsável e prazo por criticidade; se não houver movimentação, o processo registra atraso e aciona escalonamento. O almoxarifado recebe a demanda com prioridade, o PCM acompanha o aging por status e, assim que a peça é separada, a OS retorna automaticamente para programação, reduzindo tempo morto e replanejamentos de última hora.
- • KPIs: aging por status (material), % OS sem movimentação, lead time total e % OS no prazo (SLA) por criticidade.
- • Efeito operacional esperado: redução de compras emergenciais e de horas extras associadas a atrasos acumulados.
- • Monitoramento do status e prazos: acompanhamento do andamento da OS por status (aberta, aprovada, planejada, liberada, em execução, parada, concluída, encerrada) e por prazos definidos pelo processo.
- • SLA e compromissos por criticidade: permite tratar OS críticas (segurança/produção) com tempos-alvo diferentes de OS rotineiras.
- • Atribuição de responsáveis e fila de pendências: deixa explícito “quem precisa agir agora” (PCM, líder, técnico, almoxarifado, operação, terceiros).
- • Escalonamento por atraso: quando uma etapa extrapola o prazo, o sistema registra o desvio e pode escalar a notificação para níveis superiores (ex.: líder → supervisor → gerente).
- • Histórico de acompanhamento: registro de eventos (quem alterou, quando, o que foi solicitado/atualizado), útil para auditorias, lições aprendidas e melhoria de processo.
- • Integração com comunicação (Notify): o Follow-up define “o que está pendente” e o Notify entrega a mensagem no canal adequado (web, app, e-mail, integrações).
Aplicações práticas na gestão da manutenção de ativos
O Follow-up traz ganhos imediatos quando é usado como “espinha dorsal” do ritual de PCM, conectando programação, execução em campo, materiais e validação da operação. Abaixo estão aplicações típicas (com exemplos de como isso aparece no dia a dia):
- • Gestão de paradas e corretivas emergenciais: ao abrir uma OS com criticidade alta, o Follow-up força prazos curtos e visibilidade de pendências (ex.: aguardando liberação operacional, aguardando peça, aguardando técnico especialista), reduzindo tempo parado por espera.
- • PCM semanal orientado a pendências: em vez de “revisar uma planilha”, o planejador utiliza a lista de OS em atraso e em risco (próximo do vencimento), atacando gargalos (material, terceiros, permissões, janela de parada).
- • Garantia de retorno à operação: após a conclusão técnica, o Follow-up ajuda a garantir etapas de teste, inspeção final e aceite da operação (reduzindo retrabalho e falha de comissionamento).
- • Controle de dependências (peças, ferramentas, bloqueio e etiquetagem): o Follow-up evidencia OS que “não podem iniciar” por falta de pré-requisito, permitindo antecipação pelo almoxarifado e pelo PCM.
- • Padronização de disciplina: toda OS passa por um fluxo mínimo (aprovação, planejamento, execução, fechamento com causa/ação/tempo/material), elevando confiabilidade dos dados que alimentam BI e IA.
- • Transparência com a área solicitante: reduz ligações/WhatsApp perguntando status, pois o solicitante passa a receber marcos do processo (aprovada, programada, em execução, concluída).
Como reduz custos
Em manutenção, uma parte relevante do custo não está na execução em si, mas no tempo improdutivo (espera por liberação, espera por material, deslocamentos, replanejamento) e na perda de produção associada à falta de coordenação. O Follow-up reduz custos ao:
- • Reduzir tempo de espera (tempo morto): ao expor o gargalo e cobrar a próxima ação, diminui-se o tempo total de atendimento (lead time) e, em ativos críticos, o tempo de parada.
- • Evitar compras urgentes: OS “paradas por peça” aparecem rapidamente; isso permite antecipação (requisição, separação, reserva e compra planejada), reduzindo fretes expressos e compras emergenciais.
- • Diminuir retrabalho e reincidência: fechamento disciplinado com causa/ação e validação final diminui falhas repetidas por “fechamento superficial” (sem teste/sem inspeção).
- • Reduzir horas extras por desorganização: ao estabilizar o fluxo de trabalho e evitar acúmulo de atrasos, a necessidade de mutirões e horas extras tende a cair.
- • Evitar perdas por SLA interno: quando a manutenção atende áreas internas com compromissos de prazo (ex.: utilidades, refrigeração, segurança), o acompanhamento evita atrasos críticos.
Como aumenta produtividade
Produtividade na manutenção depende de reduzir interrupções e aumentar o wrench time (tempo efetivo de ferramenta na mão). O Follow-up contribui ao transformar acompanhamento informal (cobrança por mensagens, ligações e “caça” de informação) em um processo automático e rastreável.
- • Menos tempo administrativo: o PCM e a supervisão gastam menos tempo perguntando “em que pé está” e mais tempo removendo causas de atraso.
- • Programação mais estável: ao identificar rapidamente OS travadas, evita-se reprogramação de última hora e ociosidade por falta de frente de trabalho.
- • Maior taxa de fechamento correto: o sistema reforça a completude de dados (tempos, materiais, causa/ação), reduzindo retrabalho de digitação e correção posterior.
- • Melhor interface com almoxarifado: pendências de material ficam explícitas e priorizadas, reduzindo idas e vindas desnecessárias.
KPIs recomendados
| KPI | Como medir no processo | Por que importa |
|---|---|---|
| % O.S. no prazo (SLA) | OS concluídas dentro do prazo-alvo por criticidade | Mostra disciplina e previsibilidade; reduz urgências |
| Lead time de OS | Abertura → início → conclusão → encerramento | Captura tempo de espera e gargalos, além da execução |
| Aging por status | Tempo médio por etapa (aguardando liberação, material, terceiros) | Indica onde atacar para reduzir paradas e atrasos |
| % OS parada por material | OS com status “aguardando peça” / total | Ajuda a ajustar estoque, reserva e compras planejadas |
| % replanejamento | OS reprogramadas / OS programadas | Alta taxa sinaliza instabilidade e baixa aderência |
Roteiro de implantação (boas práticas)
- Desenhar o fluxo da OS: definir claramente etapas e critérios (o que significa “planejada”, “liberada”, “concluída”).
- Definir prazos por criticidade: SLAs simples (A/B/C) para aprovar, planejar e atender (principalmente corretivas).
- Amarrar responsáveis: cada etapa precisa de um dono (PCM, líder, técnico, almoxarifado, operação).
- Implantar em 2 ciclos: primeiro, focar em status/prazos; depois, reforçar qualidade do fechamento (códigos, tempos, evidências).
- • KPIs: tempo de aprovação (abertura→aprovação), tempo de resposta a alertas (alerta→primeira ação) e % OS vencidas por criticidade.
- • Boa prática: iniciar com poucos gatilhos de alto impacto para evitar “fadiga de alertas”.
- • Segmentação por perfil: mensagens diferentes para solicitante, técnico, líder, PCM, almoxarifado, engenharia e terceiros.
- • Multicanais: entrega via web, aplicativo mobile, e-mail e integrações (quando aplicável).
- • Escalonamento: se não houver ação dentro do prazo, o aviso pode escalar para outro nível de gestão.
- • Padronização do conteúdo: mensagens com dados mínimos (ativo, local, criticidade, prazo, pendência, link/identificador) para reduzir ruído.
- • Aprovações sem gargalo: notificar aprovadores quando uma OS crítica entra na fila, reduzindo tempo até liberação e início do trabalho.
- • Programação e janela operacional: avisar a operação sobre manutenções programadas, necessidade de parada, bloqueio e liberação, evitando conflitos com produção.
- • Falta de material e reserva: notificar almoxarifado quando uma OS crítica depende de peça, e notificar PCM quando a separação estiver concluída.
- • Alertas de segurança: avisos para situações críticas (ex.: falha com risco, botão de alerta/pânico em campo quando disponível no mobile).
- • Fechamento e aceite: ao concluir a OS, notificar a área solicitante para validar funcionamento e registrar aceite, reduzindo retrabalho por “conclusão sem teste”.
- • Rotina de inspeções: disparar lembretes de checklists e rotas de inspeção, elevando cumprimento do plano.
- • Menos tempo parado por espera: aprovações, liberações e materiais deixam de “ficar esquecidos” em filas.
- • Menos deslocamentos improdutivos: o técnico só se desloca quando a frente de trabalho está liberada e com pré-requisitos atendidos.
- • Menos multas/penalidades internas e contratuais: para empresas com SLAs (facilities, utilidades, contratos), o Notify reduz atrasos não percebidos.
- • Menos retrabalho de comunicação: reduz ligações/WhatsApp e reuniões para descobrir status, liberando tempo de gestão.
- • Menos interrupções na equipe: o aviso chega estruturado; evita “interromper para perguntar” e reduz ruído.
- • Mais aderência ao planejado: lembretes e confirmações reduzem esquecimento de rotinas e inspeções.
- • Mais velocidade na tomada de decisão: supervisores recebem exceções (atrasos/anomalias), em vez de monitorar tudo manualmente.
- Mapear eventos críticos: listar quais eventos realmente precisam gerar aviso (ex.: OS crítica aberta; OS em atraso; peça indisponível; OS concluída aguardando aceite).
- Definir público e canal: quem recebe o quê; quando é e-mail vs. app vs. web; e regras para terceiros.
- Evitar “fadiga de alertas”: começar com poucos avisos de alto impacto e evoluir conforme maturidade.
- Padronizar mensagens: incluir sempre ativo/local/criticidade/prazo/pendência e responsável.
- Testar por 2–4 semanas: ajustar frequência, escalonamento e horários para não gerar ruído desnecessário.
- • KPIs: % OS executadas/apontadas via mobile, tempo de fechamento da OS, % OS devolvida por dados incompletos e % OS com evidência.
- • Critério de sucesso: redução de atraso de registro e aumento de completude no fechamento.
- • Operação online/offline com sincronização: permite trabalhar sem sinal (subsolo, áreas remotas) e sincronizar quando a conectividade retorna.
- • Abertura, aprovação e conclusão de O.S. no celular: reduz filas e acelera o ciclo de atendimento.
- • Leitura de QR Code: identificação rápida do ativo e acesso ao histórico no ponto de uso.
- • Registro multimídia: inserção de imagens para rastreabilidade e suporte à execução (antes/depois, evidências).
- • Comando de voz: apoio ao registro de falhas e dados em situações em que digitar é improdutivo.
- • Autenticidade com identificação facial: reforça governança (quem abriu/aprovou/executou) e reduz risco de apontamentos indevidos.
- • Checklists dinâmicos: rotas e inspeções com formulários ajustáveis e registro imediato.
- • Corretiva com diagnóstico rápido: o operador lê o QR Code do equipamento, abre a solicitação com foto/vídeo e descrição; o PCM transforma em OS e o técnico já recebe com contexto suficiente para levar ferramentas e peças certas.
- • Preventiva sem papel: checklists e procedimentos aparecem no app; o técnico marca itens, registra medições e evidencia execução, criando histórico padronizado.
- • Inspeções e rotas: supervisores criam rotas por área/linha e o app guia a execução; não conformidades viram OS automaticamente.
- • Apontamentos no momento real: horas trabalhadas, materiais e serviços executados são lançados em campo, reduzindo erro de memória e atrasos de digitação.
- • Operação em áreas sem conectividade: modo offline evita “depois eu lanço”, que é uma das maiores causas de baixa qualidade de dados em CMMS.
- • Rastreabilidade e auditoria: evidências anexadas e autenticação fortalecem compliance e facilitam auditorias (ISO, segurança, qualidade).
- • Redução de tempo de parada: melhor qualidade de abertura (foto/vídeo/QR/histórico) acelera diagnóstico e reduz MTTR.
- • Menos deslocamentos e retornos: ir ao ativo “uma vez só”, com informação e peças adequadas, reduz custo e tempo.
- • Menos retrabalho administrativo: elimina digitação posterior e reconciliação de papéis, reduzindo horas improdutivas.
- • Menos perdas por falhas de registro: apontamentos em tempo real evitam OS encerradas “sem dados”, que impedem análise e geram manutenção repetitiva.
- • Otimização de estoque e compras: consumo real registrado no campo melhora acurácia de sobressalentes e reduz compras urgentes.
- • Mais execução, menos escritório: o técnico não precisa voltar ao computador para registrar; o trabalho “termina” no campo.
- • Menos espera por informação: histórico e procedimentos disponíveis na palma da mão.
- • Padronização em escala: checklists e campos obrigatórios reduzem variações de registro entre turnos e equipes.
- • Mais velocidade de aprovação: líderes podem aprovar e priorizar rapidamente (quando habilitado), evitando fila.
- Preparar infraestrutura: definir política de dispositivos (corporativo vs. BYOD), conectividade por área e requisitos de segurança.
- Padronizar identificação de ativos: gerar e fixar QR Codes e validar nomenclatura/locais para evitar leituras ambíguas.
- Definir perfis e permissões: o que cada papel pode abrir/aprovar/encerrar e quais campos são obrigatórios.
- Piloto por área: iniciar em uma linha/área (4–6 semanas) medindo indicadores de adoção e qualidade de registros.
- Treinamento por tarefa: focar em micro-rotinas (abrir OS com foto; apontar hora; anexar evidência; concluir com causa/ação).
- • KPIs: % OS com evidência (quando obrigatória), first-time fix rate, MTTR em ativos críticos e % retrabalho por erro de escopo.
- • Boa prática: padronizar o que é “evidência útil” (plano geral + detalhe + identificação + teste).
- • Evidência “antes e depois”: comprova condição encontrada e resultado da intervenção.
- • Suporte ao diagnóstico: ajuda PCM e especialistas a classificar e orientar sem precisar estar fisicamente no local.
- • Padronização de comunicação: reduz descrições subjetivas e aumenta clareza do sintoma.
- • Rastreabilidade e auditoria: facilita comprovação para qualidade, segurança e conformidade.
- • Base para melhoria contínua: registros visuais alimentam lições aprendidas, padrões de inspeção e análises.
- • KPIs: % OS devolvida por falta de dados, completude do fechamento e tempo médio de abertura/cadastro.
- • Efeito operacional esperado: redução de retrabalho administrativo e aumento da consistência dos registros.
- • Guias passo a passo (workflows): orienta o usuário nas etapas esperadas do processo (ex.: abrir OS com ativo + local + sintoma + criticidade + evidência).
- • Contexto por perfil: sugere ações conforme o papel do usuário (ex.: para PCM: planejar; para técnico: executar e apontar; para solicitante: validar e aceitar).
- • Redução de erros por campos obrigatórios: reforça preenchimento mínimo de qualidade (códigos, tempos, causa/ação, materiais), evitando OS “sem dado”.
- • Padronização do processo: reduz variações de procedimento entre turnos e áreas, melhorando comparabilidade de indicadores.
- • Onboarding rápido: acelera adoção de novos usuários (internos e terceiros) e reduz dependência de treinamento presencial contínuo.
- • Abertura “bem feita” na origem: orientar solicitantes a informar ativo correto (QR/seleção), sintoma, impacto (produção/segurança/qualidade), anexar evidência e indicar urgência de forma padronizada.
- • Planejamento mínimo obrigatório: guiar o PCM no preenchimento de plano de execução (procedimento, tempo padrão, recursos, ferramentas, materiais, bloqueio/etiquetagem, janela operacional).
- • Execução em campo com checklists: direcionar o técnico a registrar etapas críticas (ex.: medições, torque, ajustes) e anexar evidências antes/depois.
- • Fechamento com qualidade de causa raiz: conduzir o usuário a escolher códigos de falha/causa/ação padronizados e registrar testes finais, reduzindo reincidência por “fechamento cosmético”.
- • Integração com Follow-up/Notify: quando uma etapa não é concluída, o assistente reforça o próximo passo e o Notify aciona os envolvidos.
- • Auditorias e conformidade: padronização ajuda a comprovar que rotinas foram feitas (ex.: inspeções, lubrificação, segurança), com trilha de execução.
- • Menos retrabalho administrativo: menos OS devolvida por dados faltantes e menos correções posteriores.
- • Menos reincidência por fechamento fraco: ao forçar registro de causa/ação e validação, reduz repetição de defeitos.
- • Menor custo de treinamento: reduz horas de capacitação e necessidade de “treinamento sombra”, especialmente para terceiros.
- • Menos desperdício de sobressalentes: diagnóstico mais padronizado e registro melhor de sintomas reduz trocas por tentativa.
- • Menos falhas de compliance: em processos regulados, evita não conformidades que geram custo de auditoria e retrabalho.
- Mapear onde o processo quebra: levantar as principais causas de OS ruim (sem ativo, sem sintoma, sem evidência, sem prioridade) e os pontos de retrabalho.
- Definir padrões: dicionário de falhas/causas/ações, campos obrigatórios e critérios de criticidade.
- Desenhar guias por papel: um fluxo para solicitante, outro para PCM, outro para técnico e outro para almoxarifado.
- Piloto com usuários-chave: testar por 2–4 semanas em uma área, coletando feedback de usabilidade e ajustes de campos.
- Escalar gradualmente: após estabilizar, expandir por área/turno e incluir terceiros.
- • KPIs: backlog (semanas), % preventiva realizada, MTBF/MTTR por ativo crítico, custo por OS/ativo e lead time.
- • Critério de sucesso: decisões recorrentes baseadas em painel (uma única versão da verdade) e redução do tempo gasto com relatórios.
- • Dashboards em tempo real: visões operacionais e gerenciais com atualização contínua.
- • KPIs automáticos: cálculo padronizado de MTTR, MTBF, backlog, custos e cumprimento de preventivas.
- • Análise histórica e comparativos: tendências e benchmarking por ativo, área, equipe e período.
- • Suporte à decisão: priorização de investimentos e revisão de estratégias de manutenção.
- • KPIs: % apontamentos autenticados, divergência entre horas cobradas e registradas/autenticadas e % OS fechadas sem evidência (quando exigida).
- • Critério de sucesso: redução de ajustes manuais e maior rastreabilidade ponta a ponta.
- • Autenticação forte: reduz compartilhamento de senhas e ações “em nome de outro usuário”.
- • Rastreabilidade ponta a ponta: quem abriu, quem aprovou, quem executou, quem validou (com data/hora e local quando aplicável).
- • Conformidade e auditoria: facilita comprovação de execução de rotinas críticas (segurança, utilidades, calibração, qualidade).
- • Controle de terceiros: maior confiabilidade na gestão de mão de obra terceirizada (apontamentos, início/fim, evidências).
- • Redução de fraudes/erros: minimiza lançamentos duplicados, horas indevidas e encerramentos sem execução real.
- • Apontamento de horas em campo: iniciar e finalizar execução de OS com biometria evita lançamento posterior e reduz divergência de horas.
- • Aprovações e liberações críticas: aprovar OS de alto custo, liberar equipamento para manutenção, aceitar entrega e validar teste final com identidade confirmada.
- • Execução de rotinas reguladas: checklists de segurança, calibração e inspeções podem exigir biometria no início/fim para comprovar responsabilidade técnica.
- • Gestão de terceiros e contratos: autenticar presença e execução, gerando evidências confiáveis para medição e pagamento.
- • Redução de “encerramento administrativo”: exigir autenticação para fechamento reduz OS fechada sem execução real (ou sem evidência).
- • Menos custo de mão de obra improdutiva: reduz lançamentos indevidos e melhora precisão de apontamentos, especialmente em contratos por hora.
- • Menos disputas e glosas com terceiros: evidência de presença/execução reduz divergências em medições e pagamentos.
- • Menos custos por não conformidade: em auditorias, comprovar execução evita retrabalho, paradas e correções emergenciais.
- • Menos retrabalho por dados fracos: quando o dado é confiável, BI/IA indicam prioridades corretas, reduzindo intervenções desnecessárias.
- • Login mais rápido no campo: reduz atrito de autenticação e evita tempo perdido com senha/usuário.
- • Menos validações manuais: reduz conferências posteriores de quem executou o quê.
- • Melhor qualidade de dados: diminui esforço de conciliação e ajustes, liberando tempo do PCM.
- • Fluxo mais ágil com terceiros: facilita entrada/saída e registro de execução, reduzindo burocracia.
- Definir política e conformidade (LGPD): estabelecer base legal, transparência, retenção e governança do dado biométrico, com apoio jurídico/segurança da informação.
- Selecionar pontos de uso: começar por ações críticas (aprovar OS, iniciar/finalizar execução, encerramento, validação).
- Piloto com grupo pequeno: uma equipe e um contrato de terceiros (quando aplicável) por 4–6 semanas.
- Plano de contingência: definir como operar se biometria falhar (ex.: autenticação alternativa com justificativa e auditoria).
- Treinar e comunicar: foco em objetivo (governança e confiabilidade), evitando percepção de “controle punitivo”.
- • KPIs: reincidência (modo de falha), MTBF/MTTR antes/depois, % ações no prazo e savings estimado.
- • Critério de sucesso: redução sustentada do problema (30/60/90 dias) e padronização do que funcionou.
- • PDCA conectado ao CMMS: cada ciclo pode ser vinculado a ativos, classes de ativos, falhas recorrentes, áreas, custos e O.S. relacionadas.
- • Base em dados reais: os “Checks” usam os próprios indicadores do sistema (ex.: MTBF, MTTR, reincidência, backlog, custo) como evidência objetiva.
- • Planos de ação estruturados: ações com responsável, prazo, custo estimado e evidências (padrão 5W2H), reduzindo planos vagos.
- • Priorização por impacto: apoio do BI/IA para identificar o que atacar primeiro (ex.: Pareto de falhas/custos/paradas, criticidade de ativos).
- • Rastreabilidade e auditoria: histórico das decisões, mudanças em planos e evidências do antes/depois.
- • Padronização (sustentação): quando uma ação funciona, o ciclo converge para padronização (ex.: atualização de plano preventivo, POP, checklist, treinamento) para evitar regressão.
- • Eliminar reincidência em ativos críticos: usar o Pareto de falhas para selecionar 1–3 modos de falha prioritários e executar PDCA até reduzir reincidência em 30/60/90 dias.
- • Revisar estratégia preventiva/preditiva: quando o “Check” mostra alta corretiva em um componente, o PDCA gera ações para ajustar periodicidade, roteiro e condição de disparo, ou migrar para preditiva.
- • Reduzir MTTR por gargalo: analisar parcelas do MTTR (espera por peça, liberação, execução) e criar ações específicas (estoque mínimo, kits, janela padrão, melhoria de permissões).
- • Melhor qualidade do cadastro e dos apontamentos: PDCA para elevar preenchimento de causa/ação/tempos e reduzir OS devolvidas por incompletude.
- • Otimizar sobressalentes: PDCA para itens com alto consumo emergencial, gerando mudanças em estoque (mínimo/máximo), padronização de item e criação de kits.
- • Gestão de terceiros e contratos: PDCA orientado a indicadores de prazo, retrabalho e qualidade de entrega para redefinir SLAs, critérios de aceite e medição.
- • Menos corretivas emergenciais: reduzir reincidência e aumentar MTBF diminui custo total (mão de obra + peças + perda de produção + horas extras).
- • Menos desperdício de sobressalentes: ações de padronização, kits e estoque orientado a consumo reduzem compras urgentes e itens obsoletos.
- • Menos retrabalho e repetição: padronização (POP/checklist/treinamento) reduz falhas por execução inconsistente.
- • Melhor priorização de investimentos: ao evidenciar custo de falha e risco, o PDCA direciona CAPEX/OPEX para onde há maior retorno.
- • Menos custo “oculto” de gestão: reduzir tempo gasto com reuniões improdutivas e análise manual (planilhas e consolidações) libera capacidade do PCM.
- • Decisão mais rápida e baseada em evidência: BI/IA reduzem tempo para identificar o “top 5” de perdas e direcionar ações.
- • Menos replanejamento: ao estabilizar causas de falhas e gargalos (material/liberação), a programação semanal fica mais previsível.
- • Padronização do trabalho: ações do PDCA viram procedimentos e checklists, reduzindo variação de execução e dependência de “memória” do técnico experiente.
- • Mais execução planejada: com falhas crônicas controladas, há menos interrupções emergenciais e maior taxa de preventiva realizada.
- Escolher 1 problema de alto impacto: começar com um modo de falha recorrente (Pareto) ou com um gargalo grande de MTTR.
- Definir baseline e meta: período base (3–6 meses) e meta objetiva (ex.: reduzir reincidência em 40%).
- Montar time pequeno e dono: PCM + manutenção + operação (e engenharia/fornecedor quando necessário) com um responsável pelo ciclo.
- Executar análise com dados do SIGMA: histórico de OS, tempos, peças e evidências; usar categorias padronizadas de causa.
- Criar plano de ação com governança: 5W2H (responsável, prazo, custo, evidência esperada) e marcos de verificação.
- Fazer o Check com comparativo: comparar antes/depois; checar efeito colateral (ex.: custo de preventiva vs. redução de falhas).
- Padronizar (Act): atualizar planos preventivos, POPs, checklists, treinamentos e critérios de aceite; criar auditoria de sustentação.
- Selecionar o problema: no BI, gerar Pareto de falhas/custos/paradas e escolher 1 modo de falha (ou 1 ativo crônico) com maior impacto.
- Abrir o ciclo PDCA: registrar o tema, a meta, o período base e os KPIs que serão usados no Check (ex.: reincidência e MTTR).
- Vincular evidências e O.S. relacionadas: anexar histórico de OS, fotos/vídeos e apontamentos relevantes (principalmente das últimas ocorrências).
- Realizar análise: classificar causas prováveis (método, máquina, material, mão de obra, meio ambiente) e registrar hipótese principal; usar IA para sugerir padrões (ex.: “falha ocorre após troca de turno” ou “após manutenção X”).
- Montar plano de ação (5W2H): cadastrar ações com responsável, prazo, custo estimado, e evidência esperada (ex.: checklist atualizado, kit criado, treinamento realizado).
- Executar (Do): disparar O.S. para ações técnicas (ex.: alteração de componente, melhoria, inspeção) e tarefas administrativas (ex.: padronizar cadastro, reorganizar estoque).
- Verificar (Check): após o período de estabilização, comparar os KPIs antes/depois e registrar conclusões.
- Agir/Padronizar (Act): atualizar planos preventivos, POPs, checklists e treinar equipe; programar auditoria em 30/60/90 dias.
- • Erro: escolher um tema amplo (“melhorar manutenção”). Como evitar: recortar para 1 ativo/modo de falha/KPI específico.
- • Erro: não definir baseline e meta. Como evitar: estabelecer período base e meta numérica (ex.: -30% reincidência).
- • KPIs: tempo de detecção, tempo de resposta (alerta→primeira ação), % alertas tratados no prazo e redução de corretiva emergencial.
- • Boa prática: iniciar com 5–10 regras de alto valor e calibrar persistência para controlar falsos positivos.
- • Definição do “normal” (baseline): aprende ou parametriza comportamento esperado por ativo/classe/turno/sazonalidade.
- • Limites dinâmicos: alertas não dependem apenas de um número fixo; podem considerar tendência e desvio padrão para evitar ruído.
- • Alertas orientados à ação: o alerta já indica qual ativo, qual desvio, impacto provável e o próximo passo sugerido.
- • Prioridade por criticidade e risco: o mesmo desvio em ativos diferentes gera níveis de urgência diferentes.
- • Integração com Notify e Follow-up: alertas chegam aos responsáveis e viram pendência rastreável até a tratativa.
- • Geração de O.S. automática (quando aplicável): em cenários com telemetria/IoT, eventos podem abrir OS e disparar fluxos sem intervenção humana.
- • Redução de falsos alarmes: configurações de “persistência do desvio” (ex.: só alertar após X ocorrências/tempo) aumentam confiança no sistema.
- • Ativo entrando em comportamento “crônico”: alerta quando um mesmo ativo abre 3 OS corretivas em 15 dias (ou outra regra), disparando análise e PDCA.
- • Consumo anormal de sobressalentes: alerta quando um item de reposição começa a sair acima do padrão (sinal de desgaste, especificação incorreta ou falha de execução).
- • Desvio de MTTR/tempo de espera: identificar quando o tempo de espera por peça ou liberação cresce, sinalizando falha de processo (estoque, compras, janela operacional).
- • Preventiva “escapando”: alerta quando cumprimento de preventiva cai abaixo da meta ou quando backlog supera X semanas.
- • Alarmes e eventos de IoT/telemetria: quando integrado, eventos (temperatura, vibração, corrente, pressão, vazão) podem gerar alertas e OS baseadas em condição.
- • Qualidade do registro: alerta quando % de OS sem causa/ação/tempos aumenta, indicando perda de confiabilidade do dado.
- • Gestão de terceiros: alerta para atrasos recorrentes, retrabalho, ou aumento de OS reaberta em serviços terceirizados.
- • Evitar falhas catastróficas: intervir antes da quebra total reduz dano colateral (motor, redutor, rolamentos, acoplamentos) e risco de segurança.
- • Reduzir paradas não planejadas: antecipação permite programar janela e recursos, reduzindo impacto na produção.
- • Diminuir compras emergenciais: quando a necessidade é detectada cedo, compra-se com prazo normal e melhor preço.
- • Otimizar manutenção baseada em condição: reduzir preventiva “a mais” (troca prematura) e corretiva “a menos” (tarde demais).
- • Reduzir desperdício de materiais: consumo anormal aponta problema de execução/especificação; corrigindo a causa, reduz-se gasto recorrente.
- • Gestão por exceção: a equipe foca no que está desviando, em vez de “olhar tudo o tempo todo”.
- • Menos inspeção cega: reduz rondas que não encontram nada e direciona inspeções para ativos com indícios reais.
- • Priorização mais assertiva: backlog é ordenado por risco e evidência de degradação, não apenas por ordem de chegada.
- • Menos interrupções emergenciais: com menos falhas inesperadas, a programação semanal sofre menos rupturas.
- • Menor lead time de resposta: alertas chegam imediatamente ao responsável, acelerando a primeira ação registrada.
- Escolher sinais e indicadores: começar por indicadores já confiáveis no SIGMA (ex.: reincidência, MTTR, OS por ativo, consumo de peça, backlog).
- Definir baseline e regras: estabelecer o “normal” por classe/área/turno e configurar persistência (ex.: alertar após X ocorrências).
- Priorizar por criticidade: ajustar níveis de alerta conforme criticidade do ativo e impacto operacional.
- Piloto com poucos alertas: iniciar com 5–10 regras de alto valor e calibrar por 4–6 semanas.
- Controlar falsos positivos: ajustar limites e condições (ex.: janela de tempo, sazonalidade, ruído de registro).
- Definir playbooks: cada alerta deve ter um “o que fazer” (inspeção, abrir OS, checar estoque, chamar especialista).
- Conectar com PDCA: alertas recorrentes viram tema automático para PDCA (melhoria de causa raiz).
- Definir o cenário: “Ativo A abre 3 corretivas em 15 dias” ou “Consumo de peça X acima de Y% do normal”.
- Configurar o alerta: escolher o indicador, a janela de tempo e a condição de persistência (evitar alertar por ruído pontual).
- Definir destinatários: PCM (triagem), líder (priorização), técnico especialista (diagnóstico) e operação (janela/liberação), conforme o caso.
- Disparar Notify: o alerta gera mensagem estruturada com ativo, desvio, criticidade e prazo de resposta.
- Registrar a primeira ação: abrir inspeção/OS, verificar histórico, checar estoque, agendar janela; o Follow-up passa a cobrar a próxima etapa.
- Encerrar com evidência: registrar o que foi encontrado e o que foi feito (causa/ação/evidência).
- Se recorrente, iniciar PDCA: alertas repetidos acionam ciclo de melhoria para eliminar a causa raiz.
- • Erro: criar alertas demais (ruído). Como evitar: iniciar com poucos alertas de alto valor e expandir.
- • Erro: limiar fixo sem contexto. Como evitar: usar baseline por ativo/classe e condições de persistência.
- • Erro: alerta sem dono. Como evitar: definir responsável e SLA de resposta; usar Follow-up para cobrança.
- • Erro: não registrar a tratativa. Como evitar: exigir fechamento com causa/ação/evidência para alimentar BI/IA.
- • Erro: tratar sintoma repetidamente. Como evitar: quando o alerta se repete, converter automaticamente em tema para PDCA.
- • Critérios de avanço: >85% de OS com fechamento completo, baixa taxa de OS sem movimentação e painéis BI usados no ritual de gestão.
- • KPIs de implantação: adoção do mobile, redução de lead time e redução de tempo administrativo do PCM.
- • Qualidade do fechamento: > 85% das OS com causa/ação/tempos e materiais preenchidos (ou padrão definido) e evidência quando aplicável.
- • Disciplina de fluxo: baixa taxa de OS sem movimentação e OS vencidas sob controle.
- • Cadastros estáveis: ativos com estrutura e localização consistentes; itens de estoque padronizados.
- • Ritual de gestão implantado: reuniões com BI (diária/semana/mês) e decisões registradas.
- • Equipe treinada e em uso real: adoção do mobile e do piloto automático com baixa dependência de suporte.
- • Sinais de alerta: queda da completude de fechamento, aumento de OS sem movimentação, aumento de OS devolvidas e divergência de consumo de materiais.
- • KPIs de sustentação: % OS com dados completos, adoção do mobile e estabilidade do backlog e do cumprimento de preventivas.
- • Campos obrigatórios progressivos: começar com poucos campos críticos (ativo, sintoma, criticidade, causa/ação) e aumentar exigência conforme maturidade, para não travar o início.
- • Auditoria por amostragem (10 OS/semana): revisar qualidade do fechamento e dar retorno rápido à equipe; isso sustenta padrão melhor do que auditorias raras.
- • Kit de implantação de QR Code: padronizar impressão, fixação e manutenção das etiquetas (troca quando danifica), evitando que o QR vire “enfeite”.
- • Playbooks por tipo de alerta: para cada anomalia, ter um roteiro do que fazer (inspeção, item a medir, quem acionar) reduz tempo de resposta e evita ações erradas.
- • Uma única tela para a rotina do PCM: consolidar fila, atrasos e prioridades (Follow-up + BI) reduz planilhas paralelas e aumenta disciplina.
- • Métricas de adoção: acompanhar % OS via mobile, % OS com evidência, % OS com códigos, e publicar semanalmente (visibilidade muda comportamento).
- • Central SIGMA (Rede Industrial): Página institucional e seção de destaques do SIGMA Mobile 3.0 (Flutter), BI integrado, IA para análise de falhas e priorização, mobilidade offline e integrações: https://www.centralsigma.com.br/
- • Rede Industrial: Página institucional com descrição do SIGMA Pilot (Piloto Automático) e recursos de plataforma/telemetria: https://redeindustrial.com.br/
- • Manual SIGMA WEB (PDF): Descrição de módulos, dashboards e alertas por e-mail no ecossistema SIGMA: http://demo.universosigma.com.br/ManualSigmaWeb.pdf
- • Conteúdo público (artigos) sobre PDCA e ferramentas complementares (5W2H, Ishikawa, Pareto) para fundamentação metodológica de melhoria contínua.
- • Conteúdo público sobre detecção de anomalias e boas práticas de alertas (contexto geral) para complementar o capítulo de anomalias
Notify: comunicação por eventos e notificações inteligentes
O que é e principais características
O Notify é o mecanismo de comunicação automática do ecossistema SIGMA que transforma eventos do CMMS (criação, aprovação, mudança de status, atraso, conclusão, anomalia detectada) em mensagens acionáveis para as pessoas certas, no momento certo. Em manutenção, isso reduz o “vai e volta” informal e evita que o processo dependa da memória ou da boa vontade de alguém avisar.
Case de uso (exemplo): aprovação rápida de OS crítica e redução de tempo parado
Ao surgir uma OS classificada como crítica, o tempo entre abertura e aprovação define o tamanho da perda. Com o Notify, eventos do SIGMA CMMS (OS crítica aberta, OS em atraso, OS aguardando liberação) disparam mensagens estruturadas para o aprovador e para o responsável seguinte do fluxo, no canal adequado. Se não houver ação dentro do prazo, aplica-se escalonamento. Na prática, a aprovação deixa de depender de ligações e mensagens informais, e passa a ser um passo controlado, com rastreabilidade do tempo de resposta.
Aplicações práticas na gestão da manutenção de ativos
Como reduz custos
O Notify reduz custos ao encurtar o tempo entre “aconteceu algo” e “alguém agiu”, diminuindo paradas e evitando que o processo seja reativo. O impacto financeiro aparece principalmente em ativos críticos e em ambientes com muitos envolvidos (operação, manutenção, terceiros, almoxarifado).
Como aumenta produtividade
KPIs recomendados
| KPI | Definição | Meta típica |
|---|---|---|
| Tempo de aprovação de OS | Abertura → aprovação | Horas (para críticas) / 1–2 dias (rotina) |
| Tempo de liberação operacional | OS planejada → liberada | Reduzir tendência; eliminar “filas invisíveis” |
| Tempo de resposta a alertas | Alerta emitido → primeira ação registrada | Minutos a horas (dependendo criticidade) |
| % OS sem movimentação | OS sem atualização por X horas/dias | Baixo e decrescente |
| % OS vencidas | OS com prazo excedido | Baixo e controlado por criticidade |
Roteiro de implantação (boas práticas)
Mobilidade moderna (Android/iOS, online/offline)
O que é e principais características
O novo SIGMA Mobile 3.0, desenvolvido em Flutter, representa a modernização da mobilidade no SIGMA, com foco em performance e experiência do usuário em Android e iOS. A proposta é levar o fluxo completo de manutenção para o campo (solicitar → aprovar → executar → evidenciar → encerrar), reduzindo papel, reduzindo retrabalho e aumentando a confiabilidade do dado capturado “na fonte” (na hora e no local do evento).
Case de uso (exemplo): manutenção em área sem conectividade com fechamento no campo
Em áreas remotas (subsolo, utilidades ou pátios), a equipe executa intervenções sem sinal e costuma lançar dados depois, gerando erros e perda de histórico. Com o SIGMA Mobile 3.0 em modo online/offline, o técnico recebe a OS, executa o procedimento, registra tempos, materiais e evidências, e conclui a atividade no próprio local. Quando a conectividade retorna, a sincronização atualiza o sistema, mantendo trilha de auditoria e base de dados completa. O efeito é reduzir “OS encerrada sem dados” e acelerar a disponibilidade de informação para PCM e gestão.
Aplicações práticas na gestão da manutenção de ativos
Como reduz custos
Como aumenta produtividade
KPIs recomendados
| KPI | Como interpretar |
|---|---|
| % OS executadas e apontadas via mobile | Quanto maior, menor dependência de papel/lançamento posterior |
| % OS com evidência (foto/vídeo) | Indica rastreabilidade e qualidade do fechamento |
| Tempo de fechamento da OS | Reduz quando a equipe registra no campo |
| % OS devolvida por dados incompletos | Quanto menor, melhor padronização e governança |
| Cumprimento de checklists/rotas | Aumenta com lembretes e usabilidade do app |
Roteiro de implantação (boas práticas)
Evidências multimídia em O.S. e ativos (fotos e vídeos)
A captura de fotos e vídeos diretamente nas solicitações, ordens de serviço e registros de ativos cria uma “camada de realidade” no CMMS: evidencia condição, confirma execução, acelera diagnóstico e padroniza comunicação entre operação, manutenção e engenharia. Em ambientes industriais, onde a descrição textual é frequentemente ambígua, a evidência visual reduz interpretações erradas e retrabalho.
Case de uso (exemplo): reduzir retrabalho por diagnóstico ambíguo e comprovar entrega
Em corretivas recorrentes, descrições como “faz barulho” ou “vazamento pequeno” geram triagem incorreta e baixa preparação, aumentando idas e voltas. Ao exigir evidência na abertura (foto/vídeo do sintoma) e no fechamento (antes/depois e teste), o SIGMA CMMS reduz ambiguidade, melhora o planejamento e cria comprovação de entrega para operação, qualidade e terceiros. Além disso, o histórico visual acelera consultas futuras e suporta análises de reincidência e melhoria contínua.
Assistente de navegação e operação (Piloto Automático)
O que é e principais características
O Piloto Automático funciona como um assistente de operação dentro do ecossistema SIGMA, orientando o usuário para executar tarefas com menos atrito (menos cliques, menos dúvidas e menos erros de processo). Em manutenção, onde há alta rotatividade de usuários, múltiplos perfis (solicitante, PCM, líder, técnico, almoxarife, terceiros) e muitas telas/campos, um assistente desse tipo reduz tempo de treinamento e aumenta a padronização do fluxo.
Case de uso (exemplo): redução de OS devolvida por abertura/fechamento incompletos
Uma causa comum de retrabalho no PCM é receber solicitações sem ativo correto, sem criticidade e sem evidência; e, ao final, receber OS encerradas sem causa/ação e sem tempos. Com o Piloto Automático, o sistema guia o usuário em um fluxo mínimo por perfil (solicitante, PCM e técnico), exigindo os campos essenciais no momento certo e reduzindo variação entre turnos. Isso diminui devoluções, encurta o ciclo de tratamento e melhora a qualidade da base que alimenta BI e IA.
Aplicações práticas na gestão da manutenção de ativos
Para extrair valor, o Piloto Automático deve ser aplicado nos pontos do processo que mais geram perdas: abertura incompleta, planejamento superficial, apontamentos atrasados e encerramentos sem evidência/códigos. Exemplos práticos:
Como reduz custos
O custo de manutenção cresce quando o processo falha em capturar informação e executar com padrão. O Piloto Automático reduz custos principalmente por prevenção de erro e redução de variabilidade:
KPIs recomendados
| KPI | Definição | Objetivo prático |
|---|---|---|
| % OS devolvida por falta de dados | OS retornadas ao solicitante/técnico por incompletude | Reduzir e estabilizar próximo de zero |
| Completude do fechamento | % OS com causa/ação/tempos/materiais preenchidos | Melhorar qualidade do histórico e base para BI/IA |
| Tempo médio de cadastro/abertura | Tempo para abrir solicitação/OS com dados mínimos | Reduzir sem perder qualidade |
| Tempo de onboarding | Dias/semanas até novo usuário operar sem suporte | Reduzir curva de aprendizado |
| Conformidade de rotinas | % checklists executados e validados | Elevar disciplina e reduzir falhas por omissão |
Roteiro de implantação (boas práticas)
BI (Business Intelligence) integrado
O que é e principais características
O BI integrado consolida informações de ordens de serviço, planos, custos, tempos e disponibilidade em dashboards e relatórios dinâmicos, permitindo gestão em tempo real e análises históricas (por ativo, área, equipe, turno e período).
Case de uso (exemplo): gestão semanal por exceção com painel único
Em uma reunião semanal de PCM, em vez de consolidar planilhas, a equipe utiliza um painel do BI integrado para visualizar backlog, OS vencidas, reincidência por ativo crítico e custos por centro de custo. A análise é feita por recortes (área, turno, equipe e período) para identificar tendências e atacar gargalos específicos (ex.: aumento de tempo de espera por material). As decisões (reprogramação, revisão de plano preventivo, ajuste de estoque mínimo ou acionamento de terceiros) são tomadas a partir da mesma base de dados, reduzindo divergências e acelerando o ciclo “detectar → decidir → executar”.
Biometria e reforço de governança
O que é e principais características
A biometria no contexto do SIGMA (ex.: identificação facial e por voz, conforme disponibilidade) fortalece a governança operacional do CMMS, garantindo que ações críticas (aprovar, iniciar, concluir, apontar horas, liberar ativos, registrar evidências) estejam vinculadas a uma identidade real. Em manutenção, isso reduz riscos de apontamentos indevidos, melhora auditoria e aumenta a confiabilidade dos dados que alimentam BI e IA.
Case de uso (exemplo): controle de terceiros e rastreabilidade de apontamentos
Em serviços terceirizados ou equipes grandes, divergências de apontamento (quem executou, quando iniciou/terminou e se houve evidência) geram glosas, disputas e auditorias manuais. Ao exigir autenticação biométrica em pontos críticos (início/fim de execução, aprovação, encerramento e/ou aceite), o SIGMA CMMS vincula ações a uma identidade real, elevando governança e confiabilidade do dado. Isso reduz “encerramento administrativo” e aumenta a qualidade das medições para contratos e conformidade.
Aplicações práticas na gestão da manutenção de ativos
Como reduz custos
Como aumenta produtividade
KPIs recomendados
| KPI | Definição | Uso gerencial |
|---|---|---|
| % apontamentos autenticados | Apontamentos feitos com biometria / total | Mede aderência e confiabilidade do dado |
| Divergência contrato x execução | Diferença entre horas cobradas e registradas/autenticadas | Ataca custos de terceiros e glosas |
| % OS fechadas sem evidência | OS encerradas sem foto/vídeo/anexo quando exigido | Reduz “fechamento administrativo” |
| Tempo de auditoria/validação | Horas gastas para checar execução e conformidade | Deve reduzir com rastreabilidade |
Roteiro de implantação (boas práticas)
PDCA nativo com apoio de IA
O que é e principais características
O PDCA nativo no ecossistema SIGMA significa que a metodologia de melhoria contínua (Plan, Do, Check, Act) não fica “fora do sistema” em apresentações ou planilhas: ela é executada e registrada dentro do próprio fluxo do CMMS, conectando problema → análise → plano de ação → execução → verificação → padronização. Com o apoio de Inteligência Artificial, o processo ganha velocidade e consistência, principalmente na etapa de análise (identificação de padrões e causas prováveis) e na etapa de verificação (comparação antes/depois, checagem de efetividade e sustentação).
Case de uso (exemplo): ativo crônico com Pareto e plano 5W2H
Um ativo crítico apresenta falhas repetidas e consumo elevado de sobressalentes. A partir do BI, gera-se um Pareto de falhas/custos e seleciona-se um modo de falha prioritário. No SIGMA, abre-se um ciclo PDCA com baseline, meta e KPIs de verificação; vincula-se histórico de OS e evidências; e estrutura-se um plano 5W2H com responsáveis e prazos. As ações técnicas e administrativas são executadas e rastreadas; ao final, o “Check” compara antes/depois e, se eficaz, o “Act” atualiza plano preventivo, checklist e treinamento para sustentar o ganho.
Aplicações práticas na gestão da manutenção de ativos
O PDCA nativo, quando acoplado ao histórico do CMMS, é especialmente eficaz em três cenários: (1) ativos crônicos com falhas repetidas, (2) perdas de produção por microparadas e defeitos recorrentes e (3) desvios de processo (planejamento fraco, backlog alto, preventiva não executada). Aplicações práticas:
Como reduz custos
O PDCA reduz custos por atacar causas estruturais — e não apenas “apagar incêndio”. O apoio de IA tende a reduzir o tempo de análise e aumentar a assertividade da priorização, acelerando a captura de benefícios. Os principais vetores financeiros são:
Como aumenta produtividade
KPIs recomendados
| KPI | Definição (no contexto do PDCA) | Como usar |
|---|---|---|
| Reincidência | % de falhas repetidas (modo de falha) em 30/60/90 dias | Medir se o PDCA eliminou a causa (não só o sintoma) |
| MTBF e MTTR (antes/depois) | Comparativo do período base vs. período pós-ação | Validar impacto em confiabilidade e manutenibilidade |
| % ações no prazo | Ações concluídas dentro do prazo / total | Governança do plano de ação (disciplina) |
| Efetividade das ações | % ações que geraram melhoria comprovada | Evitar “ações cosméticas” e fortalecer aprendizado |
| Savings estimado | Economia estimada (peças + horas + paradas evitadas) | Justificar priorização e investimentos |
| Sustentação | Manutenção do resultado após 60/90 dias | Checar se padronização e treinamento fixaram o ganho |
Roteiro de implantação (boas práticas)
Exemplo de fluxo no SIGMA (passo a passo)
Erros comuns e como evitar
Detecção automática de anomalias e alertas inteligentes
O que é e principais características
A detecção automática de anomalias aplica inteligência (regras + estatística + IA, conforme o caso) para identificar, em tempo hábil, quando um ativo ou processo de manutenção está se comportando fora do padrão esperado. Em vez de esperar a falha ocorrer ou depender apenas de inspeções pontuais, o sistema passa a vigiar indicadores e sinais: aumento de frequência de falhas, consumo anormal de sobressalentes, crescimento de MTTR, repetição de chamados em curto período, queda de cumprimento de preventivas, ou eventos de telemetria/IoT em tempo real (quando disponíveis).
Case de uso (exemplo): alerta por reincidência e abertura de inspeção
Para evitar que um ativo entre em ciclo de falhas, configura-se um critério simples de anomalia (ex.: 3 corretivas em 15 dias para o mesmo ativo). Quando a condição persiste, o SIGMA emite alerta orientado à ação via Notify e cria uma pendência rastreável via Follow-up, direcionando o PCM a registrar a primeira ação: abrir uma inspeção, revisar histórico, checar consumo de peças e, se necessário, iniciar um PDCA. Ao tratar o “sinal fraco” rapidamente, reduz-se a probabilidade de uma falha maior e a ruptura da programação semanal.
Aplicações práticas na gestão da manutenção de ativos
O valor da detecção de anomalias aparece quando ela é conectada a decisões rápidas (Notify) e a execução disciplinada (Follow-up). Casos típicos de uso na manutenção de ativos:
Como reduz custos
A anomalia é, normalmente, o “sinal fraco” que antecede o problema caro. Quanto antes a manutenção age, menor o custo total. A redução de custos ocorre por:
Como aumenta produtividade
KPIs recomendados
| KPI | Definição | Por que importa |
|---|---|---|
| Tempo de detecção | Desvio ocorre → alerta emitido | Quanto menor, mais cedo se age |
| Tempo de resposta | Alerta emitido → primeira ação registrada | Mede disciplina e efetividade do fluxo Notify/Follow-up |
| % falsos positivos | Alertas sem necessidade de ação / total | Se alto, o sistema perde credibilidade |
| % alertas tratados no prazo | Alertas encerrados dentro do SLA / total | Garante que alertas gerem ação real |
| Falhas evitadas (estimado) | Eventos tratados antes da parada / total de eventos críticos | Mostra valor financeiro e operacional |
| Redução de corretiva emergencial | Corretivas emergenciais antes/depois | Efeito final esperado: menos “apagar incêndio” |
Roteiro de implantação (boas práticas)
Critérios de prontidão (quando avançar de fase)
Exemplo de fluxo no SIGMA (passo a passo)
Roadmap de adoção (quick wins vs. maturidade)
Para capturar valor rapidamente e reduzir risco, recomenda-se adotar os recursos em ondas, respeitando pré-requisitos de dados, processo e disciplina operacional. Abaixo, um roadmap sugerido que equilibra quick wins (ganhos em semanas) com recursos que exigem maturidade (governança de dados e rotina de gestão).
|
Case de uso (exemplo): implantação em ondas para reduzir risco e acelerar ganhos
Uma organização com baixa maturidade de dados tenta iniciar por IA e anomalias e não consegue sustentar resultados devido a cadastros inconsistentes e fechamentos fracos. Ao seguir um roadmap em ondas, inicia-se por disciplina de fluxo (Follow-up/Notify), padrão de cadastro e evidências; na sequência, consolida-se mobilidade e BI; e só então avança-se para PDCA com IA e anomalias. Essa abordagem reduz ruído, aumenta adesão e garante que recursos avançados operem sobre dados confiáveis, evitando frustração e retrabalho. |
Objetivo; | Recursos em foco | Entregáveis |
| 0–30 dias (base) | Padronizar processo e dado mínimo | Follow-up, Notify, evidências (foto/vídeo), padrões de cadastro | Fluxo de OS definido, SLAs por criticidade, campos obrigatórios, padrão de fechamento |
| 30–90 dias (quick wins) | Ganhar velocidade e visibilidade | Mobile (Flutter), BI integrado, piloto automático | Adoção mobile, dashboards operacionais, redução de tempo administrativo e de lead time |
| 3–6 meses (confiabilidade) | Atacar perdas crônicas | PDCA nativo + IA, IA no fluxo | Projetos PDCA em ativos críticos, redução de reincidência, melhoria de MTBF/MTTR |
| 6–12 meses (previsão) | Antecipar falhas e automatizar exceções | Detecção de anomalias, integrações IoT (quando aplicável) | Alertas calibrados, OS baseada em condição, redução de emergenciais |
Critérios de prontidão (quando avançar de fase)
Checklist de implantação e governança de dados
Este checklist serve para reduzir risco de implantação e garantir que os recursos avançados (IA, PDCA e anomalias) operem sobre dados confiáveis. Use como verificação semanal no projeto e como auditoria mensal após o go-live.
|
Case de uso (exemplo): estabilização pós go-live e sustentação de resultados
Após o go-live, a equipe percebe melhora na visibilidade, mas a qualidade dos dados começa a cair com o tempo (OS sem causa/ação, materiais sem lançamento, ativos sem criticidade). Para evitar regressão, utiliza-se o checklist como rotina de auditoria: semanalmente no projeto (implantação) e mensalmente na operação. Itens críticos — como padrão de status, SLAs por criticidade, completude de fechamento e consistência cadastral — são verificados com responsáveis definidos, e desvios geram ações corretivas (treinamento, ajustes de campos obrigatórios e reforço do fluxo via Follow-up/Notify). Assim, recursos como BI, IA, PDCA e anomalias permanecem confiáveis e úteis. |
Item de verificação | critério de aceite | Responsável |
| Processo | Fluxo de OS definido (status e critérios) | Status padronizados + definição de pronto (planejada/liberada/concluída) | PCM |
| Processo | SLAs por criticidade | Tempos-alvo definidos e comunicados (A/B/C) + escalonamento | Gestão da Manutenção |
| Dados | Cadastro de ativos (localização, criticidade, família) | > 95% dos ativos com campos mínimos preenchidos e consistentes | Engenharia/PCM |
| Dados | Códigos de falha/causa/ação | Lista padronizada + treinamento + uso em > 85% das OS | Confiabilidade |
| Pessoas | Treinamento por papel (solicitante/PCM/técnico) | Capacidade de executar rotinas sem suporte + material de referência | Implantação |
| Tecnologia | Mobile (dispositivos, permissões, offline) | App operando, QR codes válidos, sincronização testada | TI + Manutenção |
| Indicadores | Painéis BI definidos | Dashboards por nível (operação, PCM, gerência) com dicionário de KPI | Gestão |
| Segurança/LGPD | Biometria (se adotada) | Política LGPD + consentimento/base legal + contingência + auditoria | Jurídico/TI |
| Governança | Ritual de gestão | Agenda fixa (diário/semana/mês) + atas e decisões vinculadas a ações | Gestão da Manutenção |
15.1 Sugestões práticas para acelerar adesão e qualidade (recomendação)
Conclusão
A modernização da gestão da manutenção exige integrar processo, dados e execução em campo, reduzindo a distância entre o que foi planejado e o que foi efetivamente realizado. Ao combinar mobilidade (online/offline), rastreabilidade por evidências, governança de acesso (incluindo biometria quando aplicável) e disciplina de acompanhamento (Follow-up/Notify), o SIGMA CMMS fortalece o ciclo do PCM e melhora a qualidade do registro na origem. Com uma base confiável, o BI consolida indicadores e acelera decisões por exceção, enquanto IA, PDCA nativo e detecção de anomalias elevam a maturidade ao antecipar problemas e estruturar a melhoria contínua. O ganho sustentável, porém, depende de boas práticas de implantação: fluxo claro, papéis definidos, SLAs por criticidade, campos mínimos obrigatórios e auditoria recorrente. Em última instância, a tecnologia padroniza e dá visibilidade; os resultados aparecem quando a organização transforma essa visibilidade em rotina de gestão e ação consistente.


Sin comentarios aún. ¡Sé el primero en comentar!